
People
Test Bash Manchester 2019
Observability and Testing - Exploring what’s happening under the hood
@PierreVincent

Pierre Vincent compared delivering software to driving into the mist. In order to safely do this, we need to do one of two things -to slow down, or to have instruments that help us to see what’s going on in the mist. CI, however, means we are pretty much always delivering fast. Part of the reason CI is used is to deliver value fast, so to slow down is to lose this. By hurtling into the metaphorical mist, we should become comfortable with failure, therefore we must be better prepared to deal with it when we encounter it. Unit tests are not a guarantee that there are no defects - according to Vincent, we spend too much time testing on the left and not enough time looking at production and it is production where reality exists. Pre-production only tends to cover known failure modes. Pierre reinforced this by quoting Baron Schwartz - Monitoring tells you whether the system works. Observability lets you ask why it’s not working.
In order to shift our focus right, to monitoring production, we need to think about our metrics. Standard metrics are System metrics, Application metrics and Business metrics. These have a tendency to limit alerting to user impacting symptoms, are not suitable for long-term trend analysis, and offer poor fine-grained analysis. Logging should be centralised, searchable and correlated. They can be enriched with meta-data. Structured logs unleash high cardinality exploration. In order to be able to easily trace defect logs back to source, we need to implement Trace IDs. Tracing allows for high visualisation.
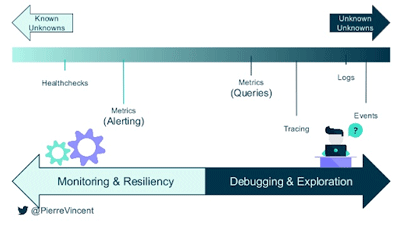
As an example of where logging has proven to be particularly effective was Amazon’s “Chaos Monkey” discipline of software experimentation. They randomly introduce things that will break systems. This needs to be well logged, otherwise all you find is that breaking things… breaks them, but if it is observable and manageable, it is a highly useful tool.
The takeaway quote from this talk, for me, was
don’t spend all of your time testing. Keep some for instrumenting.
https://www.slideshare.net/PierreVincent3/test-bash-manchester-observability-and-testing
The Wheels on the Bus Go Fail Fail Fail
@thesmartass83
@auto_he

This talk was a little lighter in tone (interspersed as it was with excerpts from an episode of The Magic School Bus Rides Again about failure and iteration - SE2EP6, available on Netflix). The overarching theme was that, as humans, we all fail, and the speakers were very enthusiastic about embracing failure. Failures, they said, are only bad if you let them stop you. Failure should be part of Plan A. It’s educational. Having an attitude of failure not being an option could lead to a toxic environment. Every failure was seen as a step towards success. They can be used for monitoring and debugging. They create teamwork. They can reveal hidden requirements. It is necessary to speak up as soon as a defect is detected, and not be afraid to do so. Where there is an atmosphere of openness around failures there is more likely to be a culture of collaboration. It is important to note, however, that failures only validates failures up until this point. It doesn’t mean that there will be no future failures (although it can provide ideas in how to locate them).
The talk ended with a quote from the teacher on The Magic Schoolbus - “Hey failures, how’s the failing.” I’m not sure I’m brave enough to say this on entering a room however.
How I Learned to be a Better Tester Through “Humble Inquiry”

Humble Inquiry, began Kwesi Peterson, is the art of drawing someone out. It is based on an idea put forward by Edgar H. Schein in his book “Humble Inquiry: The Gentle Art of Asking Instead of Telling.” Kwesi proposed that, as testers, we should become better at asking rather than telling. He went further by saying that we can solve challenges by asking not telling. In order to do this, we must become vulnerable. He then went on to discuss the use of a foundation question to ask the developers on the team - What is the key piece of information you need here? What should you be testing to give greater value to the developers? Asking questions should not be considered as being out of control. Asking questions is being in control. This ability to ask questions is useful in finding out what the customer wants, which is sometimes “Everything they wish you knew”. Kwesi said that “and what else?” were useful questions, to drill down into the real heart of an answer. Do we really know what people want? Have you really heard what people need? Make sure you understand how customers are going to deploy what you create. He also raised what he referred to as The Focus Question - What is the challenge here for you? The idea is that it is a “coaching question”. It switches focus from the problem to the person, and as a result helps them to identify the problem, and, as a result helps them to work towards a solution with them at its centre.
Relationships can be built around curiosity. Empathy needs for there to be a curiosity about others. You need to be generally interested in people for this to work. To provide an example of how people are different in ways you might not realise, he asked the room to imagine a tiger stalking across a plain. He then asked who could see the tiger clearly. He then asked who couldn’t see it at all. I’m sure I’m not alone in assuming that everyone can create images in their minds, but apparently there are those that cannot. This segued into a conversation of leadership. Leadership begins with people - if you want to be a leader, start by learning to be genuinely interested in people.
My Story of Kanban and its Positive Impact on Testing
@conorfi

Conor started with a brief overview of a place where a factory in Fremont was performing at a ridiculously low level, due to poor management and bad moral. Workers would have to be dragged in from nearby pubs, and would play little tricks like putting bottles in the body of the car, so that there was a rattling sound. Confrontation with the unions got to the point where the factory was closed down. A year later, however, Toyota joined with GM to reopen the factory, but with Toyota’s more forward thinking philosophy as opposed to GM’s archaic one. One of the major impacts of this was that “quality became everybody’s responsibility”. An Andon cord was implemented that anyone could pull. If there was a problem, it was dealt with by everyone who could rather than passed on down the line (after all, nobody could work until it was resolved). It meant that there were no quality gateways or bottlenecks. Obviously, everyone had to buy into the change, but they did (from the sounds of things, though, it wouldn’t take much for it to feel like an improvement over the old ways). You can read more about the Fremont factory here - https://medium.com/@satishbendigiri/difference-between-two-management-cultures-or-how-toyota-was-successful-where-general-motors-5e984005e1cb
Kanban is a visual representation of this process - the flow of work from one place to the next. There are a few benefits of working with kanban. Visibility leads to communication and collaboration. It can help implement a cultural shift towards a more combined way of working. It helps with creating a sustainable flow of work, and it helps working towards being able to deliver frequently. For those involved in testing, it helps reduce waste, which, in turn, helps improve quality. It helps to identify, and therefore reduce, burden. It also helps with team based testing - if there appears to be a bottleneck around testing, others can step in. Kanban makes hidden work apparent. It is also helpful in identifying issues in the workflow - a high level of work in progress means that there’s work idle. A low level of work in progress means that, through no fault of their own, there’s workers idle. Conor believes that all work, no matter how small, should be on the board before being started, and I agree. Smaller pieces of work seem to have been one of the most common themes in post mortems, and their visibility may prevent this.
Kanban Benefits:
- Visibility: Communication and Collaboration
- Culture Shift: No split between disciplines
- Sustainable Flow: Happier employees
- More frequent delivery: Happier customers
Conor put forward the idea of, in standups, looking through the Kanban board from right to left. By doing this, he believed that the thinking would be less “stop starting” and less “start finishing”. It would also lead to a move aware from testers and QAs as gatekeepers and more towards being persuaders and influencers.
Kanban as a process improvement tool:
- Visualise the workflow
- Limit work in process
- Manage flow
- Feedback loop
- Make process policies explicit
- Improve collaboratively, evolve experimentally
Lunch
As we were in Manchester, lunch was a pie with bubble and squeak, mushy peas and gravy. Marvellous, but not healthy… Kenny and I sat with a couple of testers who worked on VPN and chat solutions. It was interesting discussing the different challenges they had as testers from ours (they have to look a lot at issues of loading), and also how they dealt with co-location, as they have offices in Edinburgh, London, New Zealand, San Francisco and Cambridge.
Continuous Testing
@garyfleming
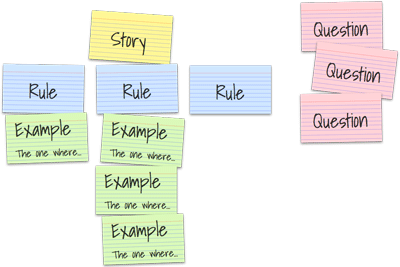
Gary Fleming started by saying that QAs and testers have never really had their day in the spotlight. This obviously got people excited from the off. He said that we needed to spread out from the “test” column and get involved in the whole process. He said that this was especially true when it came to Continuous Delivery and Continuous Integration. In order to be able to keep up with the process, we need to “shift everywhere” and the best way of doing this is by becoming quality coaches. Interestingly, of those asked in the room if they practised CI & CD, only a third of the room raised their hands. Gary made the bold (although very believable) assertion that companies that don’t quickly get on board with CI & CD will be overtaken by their competitors. He described the idea of a ‘testing’ column as being something that might lead to an ‘over the wall’, waterfall way of thinking. Instead of working in this way, he was proposing a more collaborative way of working, based around conversations. He believed that this should be a three amigos form of discussion, structured with example mapping. More can be read on example mapping here - https://cucumber.io/blog/example-mapping-introduction/, but essentially it is a method of breaking a conversation into a story, with rules beneath it, followed by examples, around which questions are formed. If there are too many of one of these elements, it would suggest that there is a problem that needs to be addressed. Too many rules might point to the chunk of work being too big, too many questions might suggest that there is a wider lack of understanding.
In order to support CI & CD, he advocated strongly for feature toggles. This allows much of what needs to be tested to go to production in a way that is safe, quick and sustainable. He left with the statement that the software development world needs more quality coaches.
Threat Modelling: How Software Survives in a Hacker’s Universe
@ms__chief

Saskia Coplans is a white hat hacker, working for a company called Digital Interruption, who talked about how you would threat model the Death Star (definitely not a banking app, as she kept saying). She recommended using data flow diagrams to map for vulnerabilities. She advocated baking in security from the beginning, as having to bring someone like her at a later point would be far more expensive. She used the mnemonic STRIDE to point out the various methods of attack:
Spoofing
Tampering
Repudiation
Information disclosure
Denial of service
Elevation of privilege
She then proceeded to map out the Death Star (and definitely not a banking app) with the areas of vulnerability and the methods of attack used. The job of a tester and pen tester are very similar, so she pushed for testers to upskill, removing the need for specialists to come in. She also stated that smaller things are easier to secure, although less things (eg APIs) was also a more secure way to go.
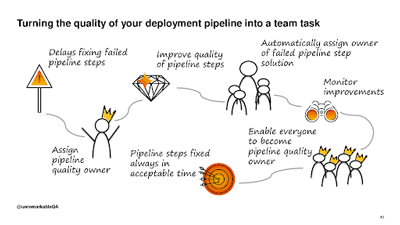
Turning the Quality of your Deployment Pipeline into a Team Task
@unremarkableQA

Areti Panou’s talk was about the bystander effect and taking charge of problems. The bystander effect is the idea that if there are a lot of people who could take charge of a problem, there is a reduced chance of somebody actually taking charge of it. She gave an example of when a piece of work was just about complete. Nobody had done the API tests, as everyone believed that they surely would have been done by someone. In the end, there proved to be a problem with the APIs and delivery was delayed. She went on to discuss the “Somebody Else’s Problem field”, which “relies on people’s natural predisposition not to see anything they don’t want to, weren’t expecting, or can’t explain.” Using this comparison, she broke it down into three areas - “How is the field activated?”, “How is the field deactivated?” and “How to keep the field inactive.”
How is the field deactivated?
The field could be deactivated, she said by removing things you don’t want to see, removing things you don’t expect to see and removing things you can’t explain.
Things you don’t want to see:
- Flaky steps
- “Place any non-deterministic test in a quarantined area (but fix quarantined tests quickly)”.
- Long running steps
- Parallelise to save time
- Complicated to fix steps
- Simplify or replace these steps
Things you don’t expect to see:
- Unresponsive external services
- Ping external services before starting the pipeline
- New unannounced steps
- Establish a new steps ritual
- Being the n-th person notified of the failed step
- Make transparent who is already working on a fix
Things you can’t explain:
- Steps with unclear purpose
- Make the value and information of the step visible
- Steps with unclear failure implications
- Make the impact and reasons of the failure transparent
- Steps with unclear fix deadlines
- Set a time limit for the fixes
How do you keep the field inactive?
- Automatically assign someone as the owner of a failed step using a deterministic rule
- The owner of a failed step should be responsible for the solution, not necessarily the fix
- Assign an owner of the quality of the pipeline rather than the pipeline steps
- Educate and enable the whole team to become owner of the quality of the pipeline
The slides can be found here - https://noti.st/unremarkableqa/CuPifH/turning-the-quality-of-your-deployment-pipeline-into-a-team-task#sitdEnD
A Code Change of Confidence
@lisihocke

The last talk of the day, by Elisabeth Hocke was more of an inspirational talk than a “testing” one, and, as such, was a particularly pleasant way to finish the day. She talked about how, as a tester, she had never really been confident about coding. To get over this, she set herself the challenge to write an app and present it at Test Bash Manchester. She set the challenge in parallel with a friend, so they ‘had to’ complete it. She recommended using a Trello board for the challenge, and set herself pause criteria - as a big fan of video games, she made sure she played at least once per week. Towards the end of the talk, she presented the app, a tool to track challenges. She finished the talk with something she had never done before - live coding a new sort method in front of an audience. Inspired by this, I’ve started coding my own thing - “Slippery Jim” - a piece of software to automatically generate testing personas (this idea stolen from the BBC’s Dora, but my plan is to make it configurable, so you can target demographics).
Home Time
After a session of 99 second talks, Test Bash was over. At the beginning, the compere, @villabone (if only I’d known he was a Villa supporter at the time :shakesfist:) said that you’d only get out of the day what you put into it, and he was right. It was a fantastic evening and day, and we got to speak to testers from all sorts of backgrounds. Some of the conversations are still ongoing online, with people happy to spend time talking. I didn’t do a 99 second talk, but I will next time, and have no excuse - the following day, having robbed some of my swag from me, my 6 year old son got up on stage during school assembly, in front of 300 kids, and told them about how his daddy had been to the BBC and brought him back a badge. If he can do it…

Codeweavers
Read more by Codeweavers